上篇类的本质中,我们知道结构体 objc_class 中的 cache 是用来方法缓存的。
cache_t 初探
cache_t 是一种用来进行快速查找执行函数的机制。我们知道 OC 为了实现其动态性,将函数地址的调用包装成了 SEL 寻找 IMP 的过程,随之带来的负面影响就是降低了方法的调用率,苹果为了解决这一问题,就引入了方法缓存的机制。
cache_t 结构
根据 libObjc objc4-756.2 版本中,cache_t 的源码:
struct cache_t { |
从源码层面不难看出,cache_t 占 16 字节。从结构上来看,bucket_t 存储了方法的 SEL 和 IMP,下面我么来验证下是否如此。
cache_t 验证
Class cls = NSClassFromString(@"SMPerson"); |
不调用方法
我们首先在方法调用前断点看看:
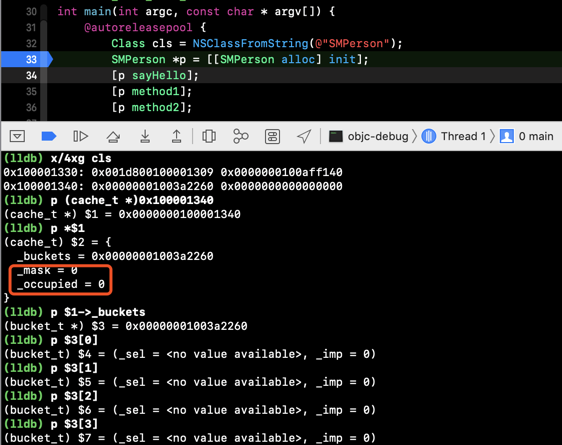
cache的地址根据cls的首地址偏移 16 个字节得到- 在方法调用之前,类中的
cache的_buckets数组是为空的,_mask和_occupied均为 0
调用一个方法
我们接着单步调试后cache 中的情况:
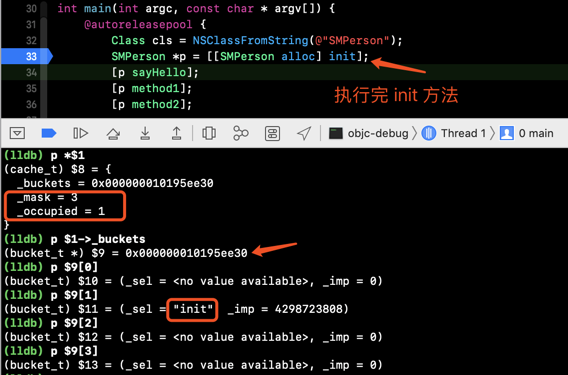
- 在调用方法之后,
cache中的值发生了变化,_occupied为 1 表示已有一位被占用 _buckets数组中有值,bucket_t缓存了方法的sel和imp- 这里需要注意的点:
buckets中的值为什么不是从下表为 0 开始
调用两个方法
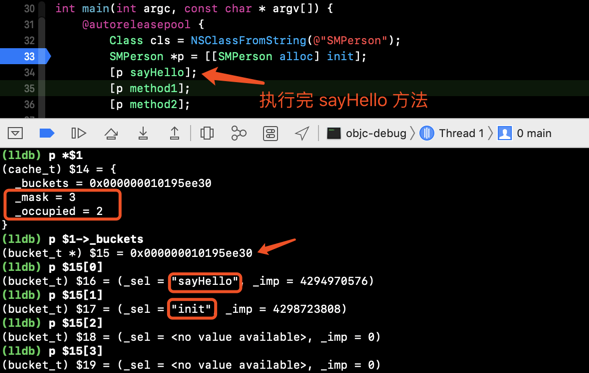
当继续执行时,调用 [p sayHello] 方法之后:
_occupied为 2, 此时增加了方法sayHello的sel和imp
此时的 _mask 为 3,_occupied 为 2,如果继续执行发生方法会发生什么呢?
调用三个方法
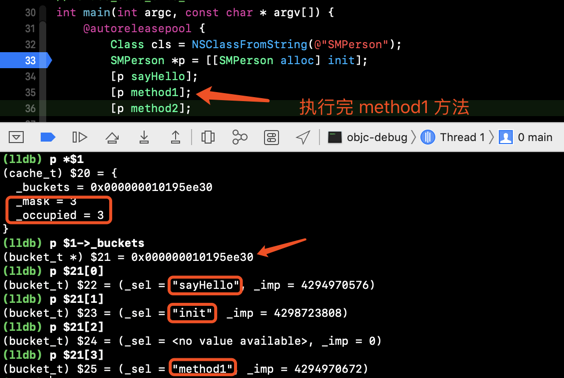
_mask为 3,_occupied为 3,新增方法method1的缓存。
调用四个方法
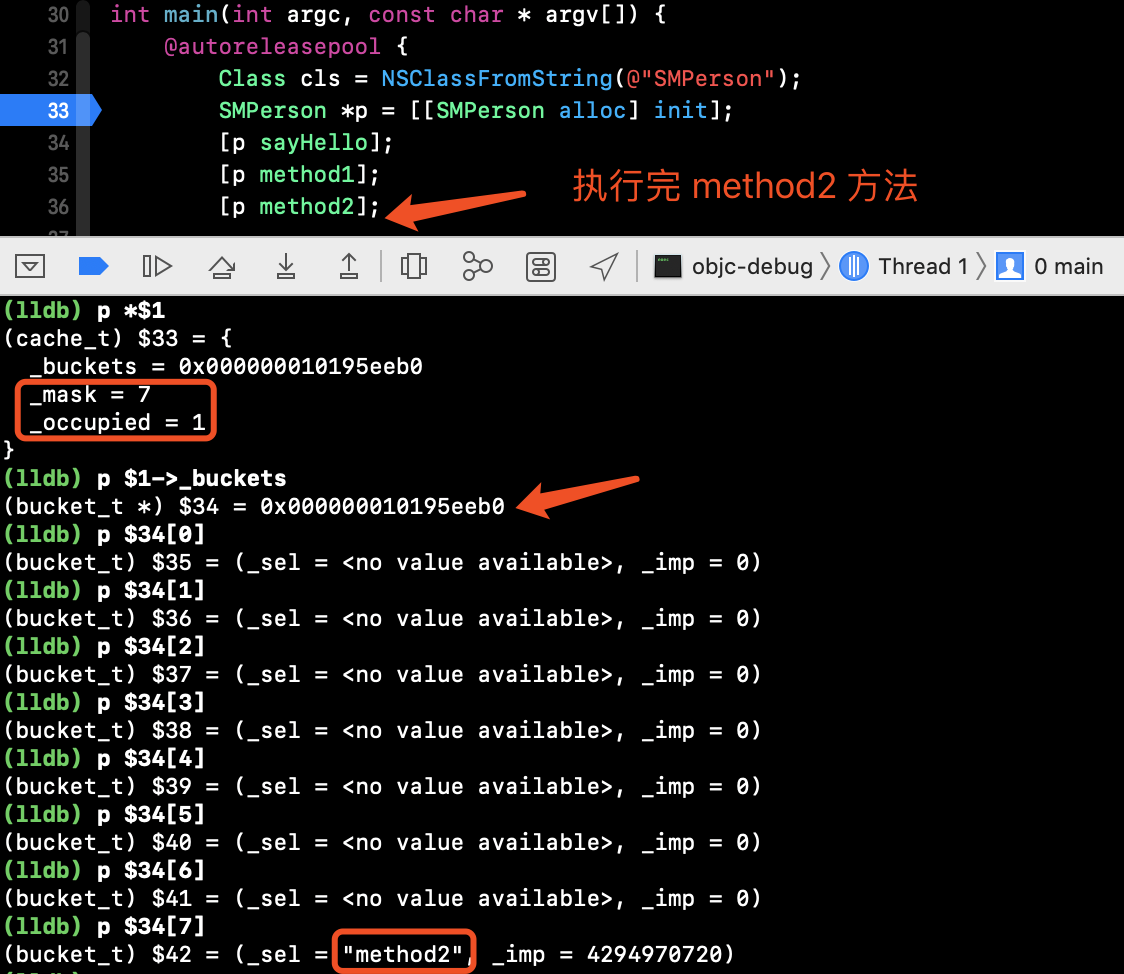
- 当继续执行
[p method2]之后,_mask为 7,_occupied为 1 - 此时
buckets的地址发生了变化
cache_t 小结
结合上面的例子,我们整理后得到:
| 调用方法 | buckets | mask | occupied |
|---|---|---|---|
| 未调用方法 | - | 0 | 0 |
| 1 | init |
3 | 1 |
| 2 | init sayHello |
3 | 2 |
| 3 | init sayHello method1 |
3 | 3 |
| 4 | method2 |
7 | 1 |
从表格中看到:
buckets:桶, 用来存储缓存的方法occupied:表示已经缓存的方法数量mask:看上去并不知道表示什么,但是结构体cache_t中有一个方法:mask_t cache_t::capacity()
{
return mask() ? mask()+1 : 0;
}所以
mask可看作是该buckets的容量
当缓存的方法数量超过其 mask 的值后,mask 的值会增大,这里很容易想到的是对缓存扩容,缓存的方法又是如何操作的呢?
cache_t 源码解析
在上面一节我们猜测,当缓存方法的数量超多某个值时会对缓存数组进行扩容,结合源码,我们发现在结构体 cache_t 中提供了两个方法:
void expand(); |
这两个方法是如何调用的呢?
在这两个方法的下面有方法 cache_fill_nolock,这个方法是提供给外部调用的 api,主要服务于 msgSend。
cache_fill_nolock
通过调用方法,触发 cache_fill_nolock,此函数查找并填充缓存:
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver) |
该方法的流程可分为三个阶段:
- 从
cls获取cache - 确定缓存容量(初始化、扩容或者直接使用)
- 根据方法
sel查找bucket,更新数组
第一个阶段很简单,我们接着看下面的过程。
确定缓存容量并开辟空间
在 cache_fill_nolock 方法中,将确定缓存的容量:
enum { |
这段代码表现为以下三种情况:
- 初始化:即原始容量为 0 时,初始化容量为 4
- 新增方法缓存后数量小于当前容量的 3/4 时:无需操作
- 扩容
reallocate 申请内存空间
如果是第一次使用缓存,肯定是第一种情况,即进行 reallocate 操作:
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity) |
这里也分为几个阶段:
- 生成新的
buckets,重新分配内存空间 - 重置
buckets的指向,更新mask的值,值为新的容量- 1,更新occupied的值为 0 - 扩容操作时会释放旧的数组,旧数组中的数据一并丢弃,即旧缓存不会并入新的数组中
扩容
当当前缓存数量占比总容量大于 3/4 时,会进行扩容,新的容量为旧容量的两倍,并重新申请内存空间
void cache_t::expand() |
更新数组
确定 buckets 后,需要更新数组中的内容:
bucket_t *bucket = cache->find(sel, receiver); |
首先通过
sel找到目标bucket:这里通过哈希算法,从而获取bucket目标
bucket的sel和imp不存在时,更新occupied的值+ 1填充
sel和impbucket_t * cache_t::find(SEL s, id receiver)
{
assert(s != 0);
bucket_t *b = buckets();
mask_t m = mask();
// 哈希算法为 s & mask
mask_t begin = cache_hash(s, m);
mask_t i = begin;
do {
/**
* b[i].sel() == 0 表示该位置还没有缓存方法
* b[i].sel() == s 命中缓存
*/
if (b[i].sel() == 0 || b[i].sel() == s) {
return &b[i];
}
// 循环条件为:最后尝试的位置 = 开始的位置
} while ((i = cache_next(i, m)) != begin); // 发生哈希冲突时,冲突函数为 cache_next
// hack
// 按照正常的逻辑,我们一定会从 buckets 中找到目标 bucket,因为 buckets 桶的课使用容量为总容量的 3/4,所以一定会命中
// 若走到这里,则将异常情况打印出来
Class cls = (Class)((uintptr_t)this - offsetof(objc_class, cache));
cache_t::bad_cache(receiver, (SEL)s, cls);
}这里涉及到两个点:
- 哈希算法:
mask和sel来确定bucket在数组中的位置 (数组的下标 =(mask_t)(uintptr_t)sel & _mask) - 哈希冲突算法:
(i+1) & _mask
- 哈希算法:
多线程与方法缓存
我们知道,方法调用时可以多线程并发执行的,那么 cache_t 在更新数据时,是如何保证线程安全的呢?
多线程同时读取缓存
在整个 objc_msgSend 过程中,为了达到最佳的性能,对方法缓存的读取操作是没有添加任何锁的,而多个线程同时调用已缓存的方法,并不会引发 _buckets 和 _mask 的变化,所以多个线程同事读取方法缓存是安全的。
多线程同时写缓存
从源码我们知道在缓存的桶的数量扩容和写数据之前,系统使用了一个全局的互斥锁 cacheUpdateLock.assertLocked() 来保证写入的同步处理,并且在锁住的的范围内还做了一次查找缓存的操作 if (cache_getImp(cls, sel)) return;,这样就避免了多个线程同时写入同一个方法,即多线程同时写缓存也是安全的。
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver) |
编译内存屏障
第一次或者扩容时,我们从新分配缓存空间,在更新 _buckets 和 _mask 时:
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask) |
这段代码中,我们先更新 _buckets 的值然后在更新 _mask 的值(更新后的 _buckets 容量一定是比旧桶的大),为了保证这个顺序不被编译器优化,使用 mega_barrier 来实现编译内存屏障。
我们在扩容后,新的容量是原来的两倍,此如果 _buckets 在 _mask 更新之后,当多线程读写数据时,此时使用新的 _mask 值来计算方法在数组中的位置,极大可能会造成数组越界,进而造成崩溃。
在使用编译内存屏障技术后,我们得到的 _buckets 数组的长度一定不小于 _mask + 1 的,如此就保证了数组不会越界。可见,借助内存编译屏障的技术可以在一定程度上实现无锁读写技术。
内存回收
在多线程读写缓存时,写线程可能正在对缓存进行扩容,在释放旧的缓存时,如果有某个线程正在读取其中的内容,此时释放就会造成一些不可预料的结果。
为了解决这个问题,在回收旧的 buckets 时,会把需要释放的 buckets 加入一个全局的数组 garbage_refs 中。等待真正没有其他线程使用数组中的元素时,在进行释放。
缓存相关的问题
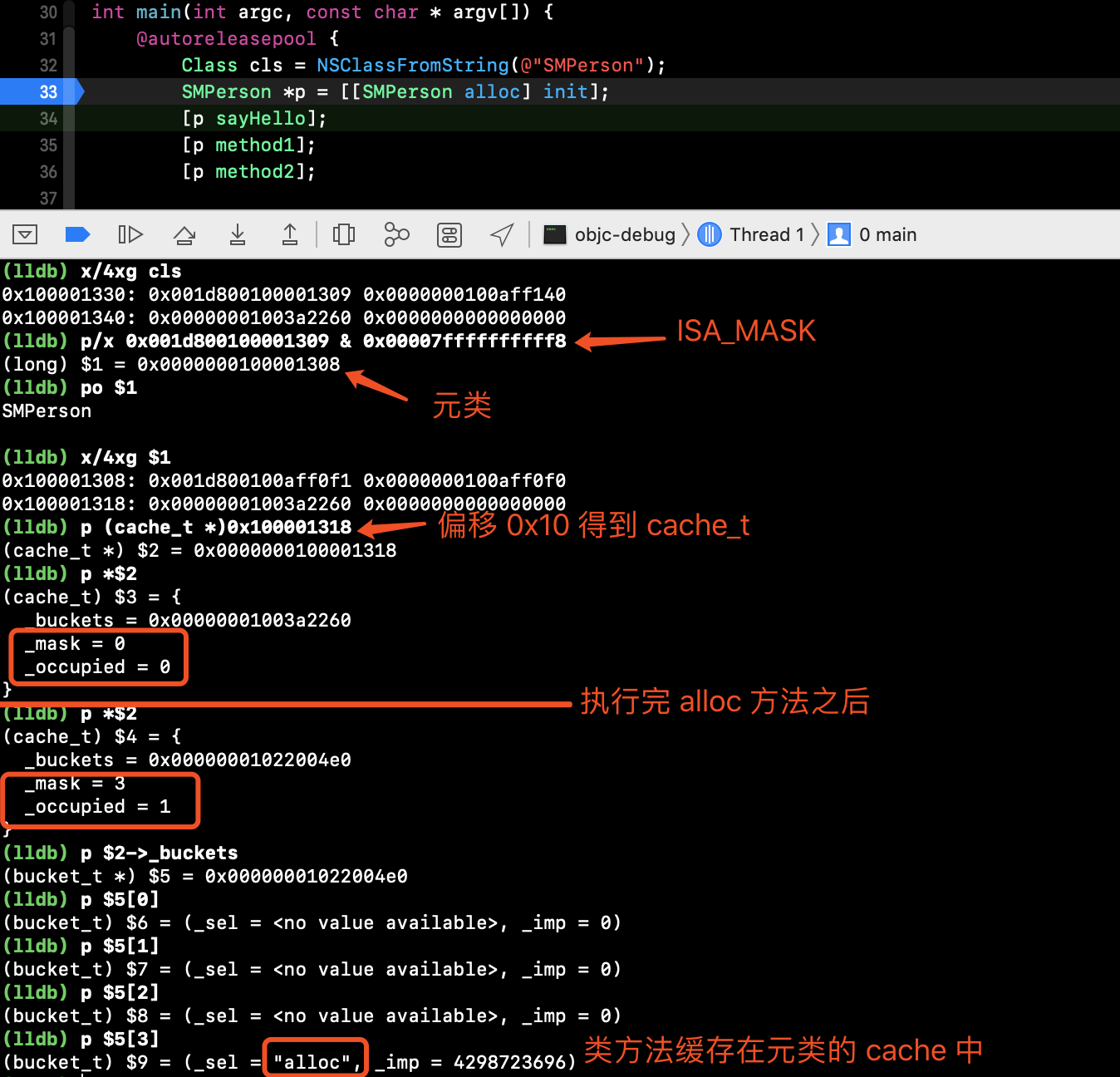
类方法缓存的位置
在上面的探索过程中,我们发现,在类的方法缓存中值有实例方法并没有类方法,如 alloc、sayHappy。
在类的本质一节中我们知道,类的实例方法存在类的 ro 中,类方法存放在元类的 ro 中。这里,实例方法缓存在类的 cache 中,那么我们是不是可以同样的猜测:类方法缓存在元类的 cache 中。
下面我们验证看看是否如此:
mask 存在的意义
在 cache_t 中:
mask_t cache_t::mask() |
_mask 反应了缓存的容量,并且保证查找哈希桶时不会出现越界的情况。
从源码中我们知道,缓存的初始容量为 4,以后每次扩容,容量增加一倍,所以缓存的容量一直是 4 的倍数。而 _mask 为容量 - 1,所以 _mask 的二进制位上都是 1。
在查找哈希桶的时候,获取数组下标(哈希函数)是由 i && _mask 得到的,这就使得下标值不会大于 _mask 的值,保证数组不会越界。
缓存扩容
当缓存的容量使用率达到 3/4 时,会进行扩容。每次扩容都是重新开辟一块内存空间,并且释放旧的缓存。旧的缓存空间缓存的数据并不会拷贝过来,这对性能是否有影响呢?
在方法调用的过程中,由于 OC 的动态性,为了提高方法调用的效率才有了方法缓存这一概念。既然是为了提高效率,就需要避免一些耗时的操作。这里直接舍弃旧的缓存空间和数据,就是一种以空间换时间的处理手段。
总结
cache_t是方法缓存的载体,实例方法缓存在类的cache中,类方法缓存在元类的cache中cache_t的三个成员变量:_buckets:是一个指针数组,又称哈希桶,存储已调用过的方法_mask:侧面表示了当前缓存的总容量,保证查找bucket时不会出现数组越界的情况_occupied:表示当前已缓存方法的数量
- 当缓存的容量使用率达到 3/4 时,会进行扩容。每次扩容都是重新开辟一块内存空间,并且释放旧的缓存。旧的缓存空间缓存的数据并不会拷贝过来
- 多线程调用方法缓存是线程安全的